 node之Buffer原理
node之Buffer原理
# 背景
- ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。 ArrayBuffer 不能直接操作,而是要通过类型数组对象 或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。
你可以把它理解为一块内存, 具体存什么需要其他的声明。
new ArrayBuffer(length);
// 参数:length 表示要创建的 ArrayBuffer 的大小,单位为字节。
// 返回值:一个指定大小的 ArrayBuffer 对象,其内容被初始化为 0。
// 异常:如果 length 大于 Number.MAX_SAFE_INTEGER(>= 2 ** 53)或为负数,则抛出一个 RangeError 异常。
2
3
4
5
- Unit8Array
Uint8Array 数组类型表示一个 8 位无符号整型数组,创建时内容被初始化为 0。 创建完后,可以以对象的方式或使用数组下标索引的方式引用数组中的元素。
// 来自长度
var uint8 = new Uint8Array(2);
uint8[0] = 42;
console.log(uint8[0]); // 42
console.log(uint8.length); // 2 一共占了多少个字节
console.log(uint8.BYTES_PER_ELEMENT); // 1 每一个元素所占的字节数
// 来自数组
var arr = new Uint8Array([21, 31]);
console.log(arr[1]); // 31
// 来自另一个 TypedArray
var x = new Uint8Array([21, 31]);
var y = new Uint8Array(x);
console.log(y[0]); // 21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- ArrayBuffer 和 TypedArray 的关系
TypedArray: Unit8Array, Int32Array 这些都是 TypedArray, 那些 Uint32Array 也好,Int16Array 也好,都是给 ArrayBuffer 提供了一个 “View”,MDN 上的原话叫做 “Multiple views on the same data”,对它们进行下标读写,最终都会反应到它所建立在的 ArrayBuffer 之上。
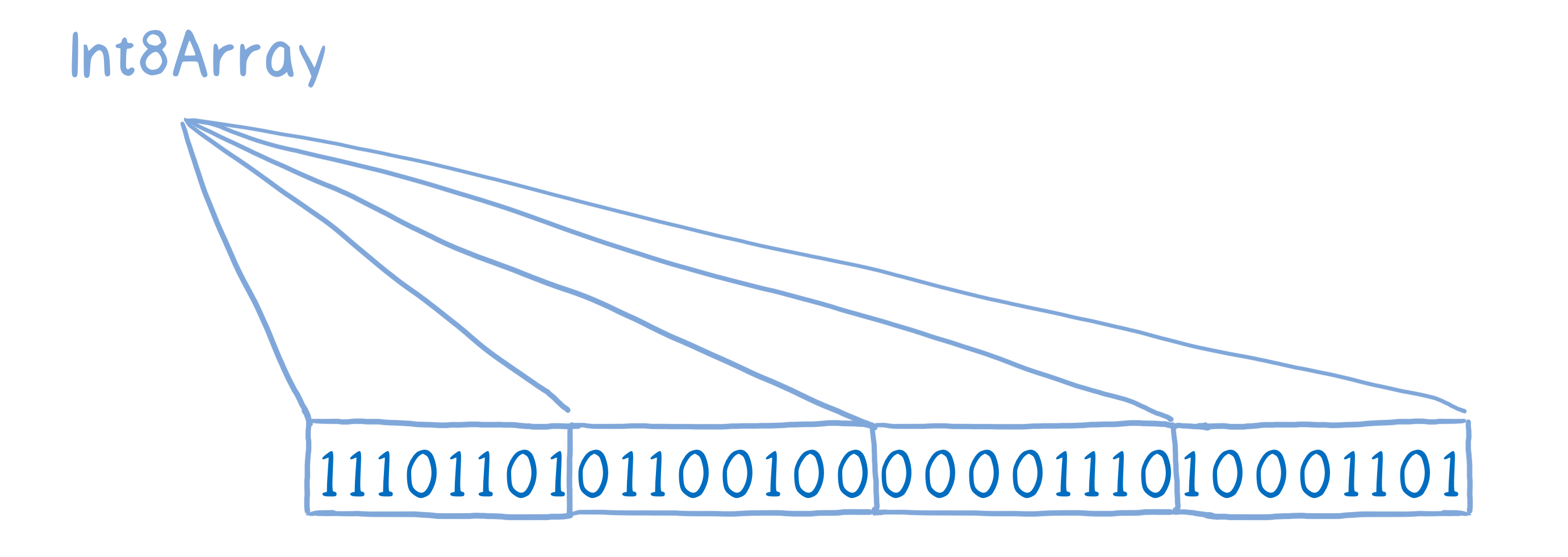
ArrayBuffer 本身只是一个 0 和 1 存放在一行里面的一个集合,ArrayBuffer 不知道第一个和第二个元素在数组中该如何分配。 // 看 array-buffer.png
为了能提供上下文,我们需要将其封装在一个叫做 View 的东西里面。这些在数据上的 View 可以被添加进确定类型的数组,而且我们有很多种确定类型的数据可以使用。
3.1 例如,你可以使用一个 Int8 的确定类型数组来分离存放 8 位二进制字节。
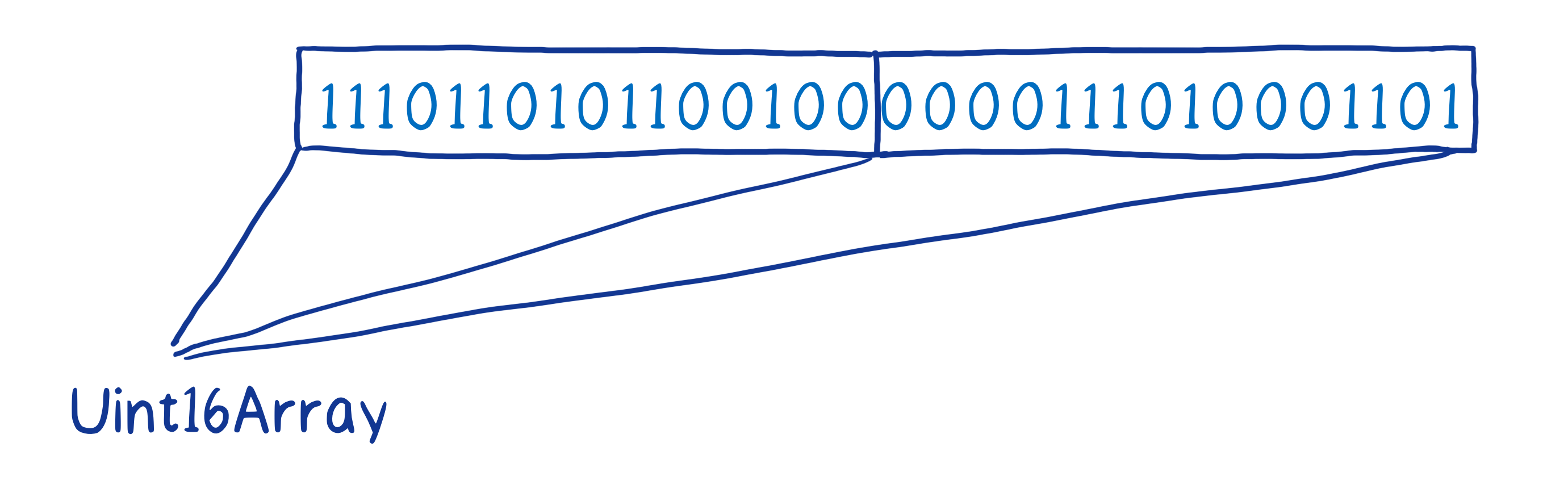
3.2 例如,你可以使用一个无符号的 Int16 数组来分离存放 16 位二进制字节。
我们了解了 buffer 是什么之后,来看看 node 的 buffer
# Nodejs 的 Buffer
Buffer 类以一种更优化、更适合 Node.js 用例的方式实现了 Uint8Array API.Buffer 类的实例类似于整数数组,Nodejs 的 Buffer 的大小是固定的、且在 V8 堆外分配物理内存。 Buffer 的大小在被创建时确定,且无法调整
# 使用
// 创建一个长度为 16、且用 0 填充的 Buffer。
const buf1 = Buffer.alloc(16);
// 创建一个长度为 16、且用 0x1 填充的 Buffer。
const buf2 = Buffer.alloc(16, 1);
// 创建一个长度为 16、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,但是返回的buffer实例的缓冲区里可能包含旧数据
// 因此需要使用 fill() 或 write() 重写。
const buf3 = Buffer.allocUnsafe(16);
// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);
// 创建一个包含 UTF-8 字节 的 Buffer。
const buf5 = Buffer.from("tést");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
要注意:
当使用 Buffer.allocUnsafe()来创建 Buffer 实例的时候,被分配的内存段是未初始化的(没有用 0 进行填充)虽然它的 速度非常的快,但是使用不当,留有了隐秘的旧数据,可能会带来安全漏洞。
# Buffer 与字符编码
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
const buf = Buffer.from("hello world", "ascii");
console.log(buf);
// 输出 68656c6c6f20776f726c64
console.log(buf.toString("hex"));
// 输出 aGVsbG8gd29ybGQ=
console.log(buf.toString("base64"));
2
3
4
5
6
7
8
9
Node.js 目前支持的字符编码包括:
- 'ascii' - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- 'utf8' - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- 'utf16le' - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- 'ucs2' - 'utf16le' 的别名。
- 'base64' - Base64 编码。当从字符串创建 Buffer 时,按照 RFC4648 第 5 章的规定,这种编码也将正确地接受 “URL 与文件名安全字母表”。
- 'latin1' - 一种把 Buffer 编码成一字节编码的字符串的方式(由 IANA 定义在 RFC1345 第 63 页,用作 Latin-1 补充块与 C0/C1 控制码)。
- 'binary' - 'latin1' 的别名。
- 'hex' - 将每个字节编码为两个十六进制字符。
# Buffer 内存管理
在介绍 Buffer 内存管理之前,我们要先来介绍一下 Buffer 内部的 8K 内存池。
# 8K 内存池
- 在 Node.js 应用程序启动时,为了方便地、高效地使用 Buffer,会创建一个大小为 8K 的内存池。
Buffer.poolSize = 8 * 1024; // 8K
var poolSize, poolOffset, allocPool;
// 创建内存池
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
poolOffset = 0;
}
createPool();
2
3
4
5
6
7
8
9
10
11
- 在 createPool() 函数中,通过调用 createUnsafeArrayBuffer() 函数来创建 poolSize(即 8K)的 ArrayBuffer 对象。createUnsafeArrayBuffer() 函数的实现如下:
function createUnsafeArrayBuffer(size) {
zeroFill[0] = 0;
try {
return new ArrayBuffer(size); // 创建指定size大小的ArrayBuffer对象,其内容被初始化为0。
} finally {
zeroFill[0] = 1;
}
}
2
3
4
5
6
7
8
这里你只需知道 Node.js 应用程序启动时,内部有个 8K 的内存池即可。
- 那接下来我们要介绍哪个对象呢?在前面的预备知识部分,我们简单介绍了 ArrayBuffer 和 Unit8Array 相关的基础知识,而 ArrayBuffer 的应用在 8K 的内存池部分的已经介绍过了。那接下来当然要轮到 Unit8Array 了,我们再来回顾一下它的语法:
Uint8Array(length);
Uint8Array(typedArray);
Uint8Array(object);
Uint8Array(buffer [, byteOffset [, length]]);
2
3
4
其实除了 Buffer 类外,还有一个 FastBuffer 类,该类的声明如下:
class FastBuffer extends Uint8Array {
constructor(arg1, arg2, arg3) {
super(arg1, arg2, arg3);
}
}
2
3
4
5
是不是知道 Uint8Array 用在哪里了,在 FastBuffer 类的构造函数中,通过调用 Uint8Array(buffer [, byteOffset [, length]]) 来创建 Uint8Array 对象。
- 那么现在问题来了,FastBuffer 有什么用?它和 Buffer 类有什么关系?带着这两个问题,我们先来一起分析下面的简单示例:
const buf = Buffer.from("semlinker");
console.log(buf); // <Buffer 73 65 6d 6c 69 6e 6b 65 72>
2
为什么输出了一串数字, 我们创建的字符串呢? 来看一下源码
/**
* Functionally equivalent to Buffer(arg, encoding) but throws a TypeError
* if value is a number.
* Buffer.from(str[, encoding])
* Buffer.from(array)
* Buffer.from(buffer)
* Buffer.from(arrayBuffer[, byteOffset[, length]])
**/
Buffer.from = function from(value, encodingOrOffset, length) {
if (typeof value === "string") return fromString(value, encodingOrOffset);
// 处理其它数据类型,省略异常处理等其它代码
if (isAnyArrayBuffer(value))
return fromArrayBuffer(value, encodingOrOffset, length);
var b = fromObject(value);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看出 Buffer.from() 工厂函数,支持基于多种数据类型(string、array、buffer 等)创建 Buffer 对象。对于字符串类型的数据,内部调用 fromString(value, encodingOrOffset) 方法来创建 Buffer 对象。
是时候来会一会 fromString() 方法了,它内部实现如下:
function fromString(string, encoding) {
var length;
if (typeof encoding !== "string" || encoding.length === 0) {
if (string.length === 0) return new FastBuffer();
// 若未设置编码,则默认使用utf8编码。
encoding = "utf8";
// 使用 buffer binding 提供的方法计算string的长度
length = byteLengthUtf8(string);
} else {
// 基于指定的 encoding 计算string的长度
length = byteLength(string, encoding, true);
if (length === -1)
throw new errors.TypeError("ERR_UNKNOWN_ENCODING", encoding);
if (string.length === 0) return new FastBuffer();
}
// 当字符串所需字节数大于4KB,则直接进行内存分配
if (length >= Buffer.poolSize >>> 1)
// 使用 buffer binding 提供的方法,创建buffer对象
return createFromString(string, encoding);
// 当剩余的空间小于所需的字节长度,则先重新申请8K内存
if (length > poolSize - poolOffset)
// allocPool = createUnsafeArrayBuffer(8K); poolOffset = 0;
createPool();
// 创建 FastBuffer 对象,并写入数据。
var b = new FastBuffer(allocPool, poolOffset, length);
const actual = b.write(string, encoding);
if (actual !== length) {
// byteLength() may overestimate. That's a rare case, though.
b = new FastBuffer(allocPool, poolOffset, actual);
}
// 更新pool的偏移
poolOffset += actual;
alignPool();
return b;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
所以我们得到这样的结论
- 当未设置编码的时候,默认使用 utf8 编码;
- 当字符串所需字节数大于 4KB,则直接进行内存分配;
- 当字符串所需字节数小于 4KB,但超过预分配的 8K 内存池的剩余空间,则重新申请 8K 的内存池;
- 调用 new FastBuffer(allocPool, poolOffset, length) 创建 FastBuffer 对象,进行数据存储,数据成功保存后,会进行长度校验、更新 poolOffset 偏移量和字节对齐等操作。